Student Post on the Promise and Privacy Concerns of Retrieval Augmentation Generation
by Andrew Dang, 3L Student, Sandra Day O’Connor College of Law – Arizona State University
Ambiguous Privacy Laws
On April 5, 2024, members of U.S. Congress released drafts of a federal privacy bill, the American Privacy Right Act (“Privacy Act”). However, like most AI bills, the Privacy Act is broad and ambiguous. The Bill attempts to be “a national data privacy and security standard that gives people the right to control their personal information.” A comprehensive privacy standard is possible when clear guidelines are given. Instead, the terms like ‘covered algorithms’ and ‘covered data’ are defined too broadly. These nebulous definitions leave a lot of room for developers to worry that their new app or software could be shut down by overzealous regulators. By extension, the EU takes a similar approach, emphasizing the call for transparency and data security without proper procedures. Regulating emerging technology is never easy due to the mercurial nature and shifting goalposts but I worry that the regulations shift risk onto developers in a way that will kill innovation and development.
Understanding and engaging with the technology at the heart of these regulations—like Retrieval Augmentation Generation (RAG)—can turn potential risks into opportunities. By grasping how such technologies work and can be regulated, developers and lawyers can better advocate for reasonable regulations that protect privacy without hampering technological advancement. Given the ambiguous nature of current privacy laws and their often-unclear guidelines, the urgency of employing a broad range of privacy measures like synthetic data, PII masking, and Homomorphic Encryption (HE). Legal professionals are advised to proactively implement these safeguards to mitigate risks and ensure compliance in a rapidly changing legal landscape.
Promise of Rag
The lawyer’s job is to navigate through the law’s complex terrain. Litigators conduct hours of legal research to strengthen their case. Litigators must deal with the discovery process, filtering out facts pertinent to the case. As for transactional law, contracts are complex because of their structure. Rarely are the terms of an agreement fully defined. Rather, the terms are scattered throughout the document. Lawyers must employ rigorous cognitive analysis to interpret and synthesize complex information. Yet, generative AI tools such as Retrieval Augmentation Generation (RAG) can reduce the cognitive constraint for lawyers.
RAG holds promise in the legal domain. RAG is a technique that enhances the ability of a large language model to generate relevant and correct responses by using external sources of information. RAG technology has shown promising results in enhancing the accuracy and relevance of responses generated by large language models (LLMs). That said, RAG truly shines when combined with Natural Language Processing (NLP). For instance, Name Entity Recognition (NER) allows lawyers to extract entities such as people, places, or organizations from large corpora or text. NER excels when documents have complex fact patterns with multiple parties.
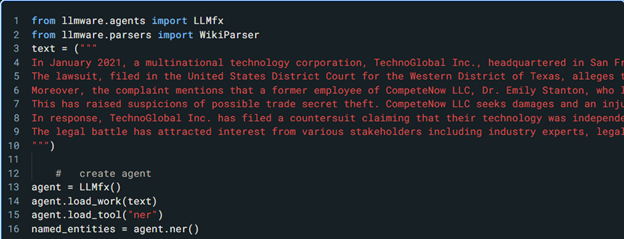
Figure 1. llmware slim models https://huggingface.co/llmware/slim-ner-tool

In addition, BERT models are trained to classify unfair clauses in Terms of Service . Other implementations of Retrieval Augmentation exist, such as summarization, sentiment analysis, and question answering tasks. Although generative AI like RAG can make lawyers more effective in their career, Cornell’s research highlights privacy and security concerns. At the state and federal level, legislators are changing and implementing new privacy laws into practice in light of AI’s emergence. Though approaches may vary, the core of privacy is anonymity. Legal professionals should understand vulnerabilities associated with RAG.
Privacy Vulnerabilities
In the paper “Text Embeddings Reveal (Almost) As Much as Text”, Cornell University trained a model to invert embeddings. For simplicity, embeddings transform words or sentences into dense vectors of real numbers within a continuous vector space. These vectors store the contextual and semantic significance of each word. When a user submits a semantic query, the search system aims to understand their intent and the context. According to the paper, Cornell researchers trained their model to reverse engineer the numerical embeddings back to plain English. This process, known as “embedding inversion,” proves that dense text embeddings retain a significant amount of information from the original text.
- Text Recovery Accuracy: The Vec2Text model recovered 92% of 32-token text inputs exactly from their embeddings. This high level of accuracy in recovering the original text from embeddings underscores the potential privacy risks associated with embedding-based representations of text.
- BLEU Score Performance: For web documents encoded with modern black-box encoders, the Vec2Text method achieved a near-perfect BLEU score of 97.3, conveying substantial fidelity in the reconstructed text compared to the original.
- Recovery of Personal Information: In clinical notes from the MIMIC dataset, the model recovered 89% of full names. Medical data can reveal a person’s predispositions and vulnerabilities. Thus, HIPAA requires covered entities to implement physical, technical, and administrative safeguards to protect Personal Health Information.
- Effectiveness Across Different Domains: The model’s effectiveness was tested across various domains using the BEIR benchmark datasets. For example, in the Quora dataset, the model recovered exactly 66% of examples, showing the model’s adaptability to different text lengths and domains.
While traditional encryption such as symmetric (e.g., AES) and asymmetric (e.g., RSA) can safeguard data, traditional encryption is not well-suited for protecting embeddings due to the unique properties of vectors. Traditional encryption destroys the semantic properties of vector representations important for tasks like similarity search and classification.
GAI tools such as RAG present privacy challenges. Even so, to forgo an efficient tool in the competitive legal environment is not practical. Premium models such as GPT-4 compete with junior associates in contract analysis and issue spotting. Firms opting out of RAG applications will be at a disadvantage. The solution then is to implement privacy practices such as de-identification. The goal would be to mask personal information from unstructured text before creating the embeddings.
A possible way to anonymize names is to use token classification. Token classification assigns a label to each word in a sentence. One type of token classification is Named Entity Recognition (NER). NER tries to identify a label for each entity in a sentence, such as a person, place, or group. On April 2, 2024, Ai4Privacy published the largest privacy dataset on Hugging Face. The dataset can help to train and evaluate models that can remove personal and sensitive information from text, especially for AI assistants and LLMs.
A possible pipeline to include is LlamaIndex. LlamaIndex offers the necessary tools to process, organize, and retrieve private or domain-specific data and use them securely and dependably in LLMs for better text generation. The examples below show how LlamaIndex and AI4 privacy’s model work together.
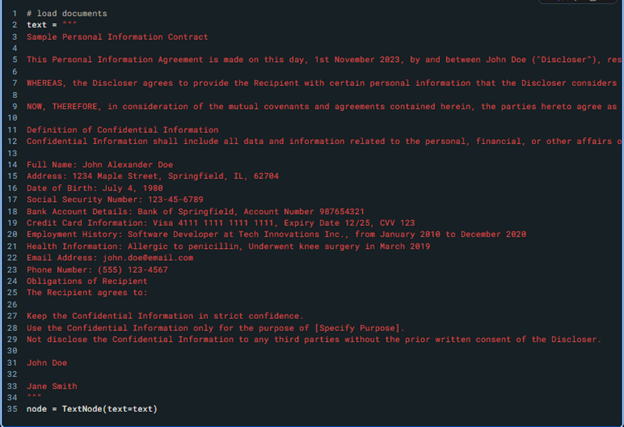
Figure 4. Here we see a sample contract with identified information such as names, places and organizations
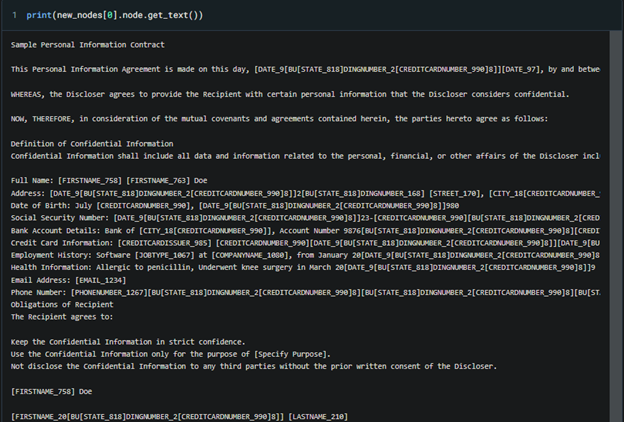
Figure 5. After applying LlamaIndex node post processors and AI4 privacy’s model we see that the entities are masked AI4 privacy model we see that the entities are masked https://huggingface.co/Isotonic/deberta-v3-base_finetuned_ai4privacy_v2
Although the example deals with contracts, masking PII is useful in other situations, such as discovery. The discovery phase in litigation involves the exchange of information held by each party. The discovery phase is exhaustive and time-consuming, as legal teams need to sift through vast amounts of data to identify material information. RAG systems can streamline the discovery process by automating the retrieval and analysis of relevant documents.
But in the early stages of discovery, sensitive information may be exposed unnecessarily. Masking PII safeguards client confidentiality but also meets legal standards that restrict data disclosure. Another example is mergers and acquisitions. During mergers and acquisitions, lawyers review documents to assess legal risks. Masking PII in these documents before using RAG models to prevent the unintended release of confidential information such as employee, customer, or corporate data.
However, masking PII has drawbacks. Redactions reduce the model’s context, which may affect the retrieval quality. For example, in family law, custody disputes depend on a full understanding of the family dynamics. Therefore, other privacy technologies that can work in tandem with (RAG) should be considered such as Homomorphic Encryption (HE).
Homomorphic Encryption
Homomorphic Encryption (HE) is a type of encryption that allows calculations on encrypted data without the need for decryption. In short, HE encryption does not ruin semantic properties from embeddings. HE is particularly useful in scenarios where sensitive data needs to be analyzed or manipulated by third parties—such as cloud computing services—without exposing the actual data. For more information on HE encryptions, legal professionals and engineers should visit Zama’s repo on Hugging Face.
Other privacy enhancing technologies exist, such as Gaussian noise and Guardrails AI’s PII validators. Legal professionals are advised to proactively implement these safeguards to mitigate risks and ensure compliance in a rapidly changing legal landscape. This forward-looking approach not only aids in navigating current regulations but also in shaping future ones to foster innovation while ensuring data security and transparency.