Predict.Law – January 15, 2026 Codex Group Meeting

Presenters: Pat Wilburn (CEO) and Dave Contreras (CTO)
The Problem
Predict.Law addresses a $61 billion market inefficiency in personal injury cases. Attorneys currently rely on outdated methods to value cases: informal hallway discussions, personal memory, and legacy search tools that feel like “web search circa 1998.”
The Solution
An AI-native platform that analyzes cases against 20,000+ precedent cases and 200,000+ data points to:
- Instantly determine case value
- Identify similar precedent cases
- Automate case workflows
Key Features
Case Valuation: Upload case documents (intake forms, medical records, etc.) and receive a predicted award value in 10 seconds, based on jurisdiction-specific data down to the county level.
Injury Analysis: Creates two severity scores using AMA guidelines—one for current impact, one for ongoing life impairment. The system can interpolate missing information (like medical expenses) early in a case.
Precedent Matching: Returns similar cases from the same jurisdiction with similarity scores, complete with court docket access and verified jury verdict sheets to ensure authenticity.
Workflow Automation: Automatically generates demand letters (including case value and precedent cases) and professional case reports for clients, counterparties, or litigation lenders.
Data Sources
- 70% verdicts, 30% published settlements from licensed national providers
- Direct county court data
- Growing data consortium where plaintiff firms share anonymized case histories to counter insurance companies’ data advantages
Market Position
Focuses on being the first tool firms use when evaluating new cases—before medical chronologies or demand letters. This early position in the workflow allows them to add value throughout the case lifecycle while helping firms work more efficiently and potentially take on lower-value cases that were previously uneconomical.
Transcript
Roland Vogl – Executive Director, CodeX:
Welcome everyone to the Codex group meeting. We’re excited for you to join us. We have a presentation today by Pat Wilburn and Dave Contreras. Pat is the CEO of Predict.Law and Dave is the CTO. Predict.Law is a legal analytics platform specifically focused on personal injury cases, and we’re thrilled to have you.
One more quick announcement: Robert Mahari and I will be traveling. Our associate director and I will be in Davos where Robert is organizing and hosting an event that Codex is co-sponsoring. There won’t be any meetings in the next two weeks. We’ll be convening again in early February. With that, I will turn it over to Pat.
Introduction – Pat Wilburn
Thank you. Nice to meet virtually all the folks on the call. Just a quick introduction on myself. I, along with Dave, are the co-founders of Predict.Law. Very briefly, prior to launching this company, I was the chief strategy officer for Thomson Reuters. Most folks know TR are the largest player in the legal tech industry. Part of that I spent a number of years at Microsoft.
Why We Launched This Company
We focus on the personal injury space. The inception story behind why we launched Predict.Law was we looked at the $61 billion of case value every year in the US from personal injury cases and started to ask what we thought were pretty basic questions to attorneys around the country: For that $61 billion in annual case value across these personal injury cases, how do you actually determine what a case is worth?
What we found were answers that were, in our view, surprisingly legacy. For example, a plaintiff firm in Seattle, a midsize firm, said, “I walk down the hallway and brainstorm with my colleagues.” The owner of what I think is the largest PI firm in Maryland said, “Well, I tend to rely on my own memory. This case feels like a case from seven years ago. It’s similar, but different.” It’s kind of a human heuristic model. You hear from folks who are using legacy tools where you enter in some search terms and receive a bunch of links with precedent cases. It feels like web search circa 1998.
We determined from all of these conversations that there must be a more modern, AI-native way to approach this core question.
Platform Demo
What I’ll show you here is a demo of the Predict.Law platform, which fundamentally is an AI-native platform that helps attorneys and law firms very efficiently understand the value of their case based on north of 20,000 precedent cases and then automate, through data-driven workflows, the process of handling and monetizing that case on behalf of their client.
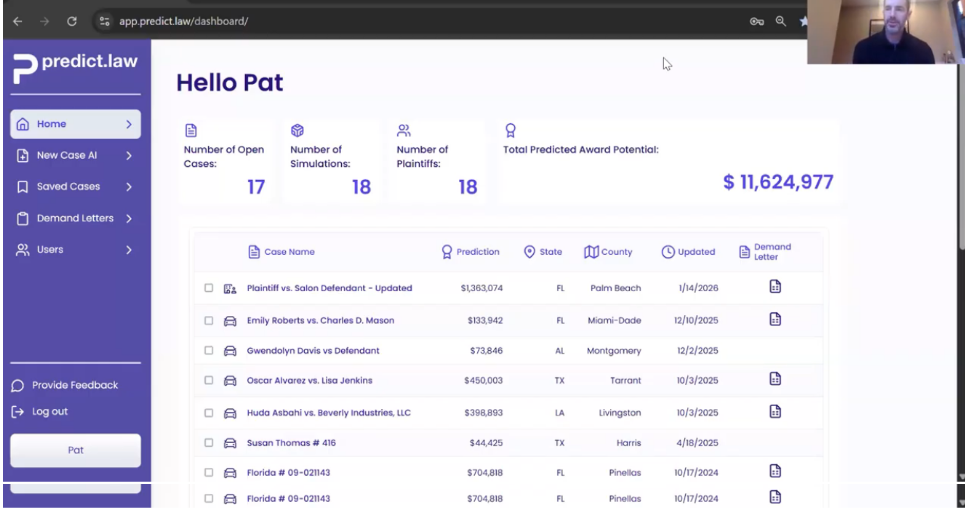
Home Screen Overview
This, as I’m sure you’ve assumed, is the home screen for an attorney and/or their support staff who’ve logged into the Predict.Law platform. What you immediately see is a list of all the cases that are active in this firm: the case names, the jurisdiction, the timestamp, but importantly, the likely value of each of those cases, as well as you can see on the far right if a demand letter has been created on our platform.
The reason we created a summary view for the top of the home screen is we heard feedback from a managing partner, I believe in New York, who told us, “My law firm is also a business, and I have the same revenue pipeline and revenue tracking needs as any other business. Because the Predict.Law platform knows and understands the value of my case, you’re also in a unique position to tell me how I’m tracking against my revenue goals as a firm.”
In the top view in this case, you can see this firm we’re using in this example has $11.6 million in case value that’s active in the pipeline.
Creating a New Case
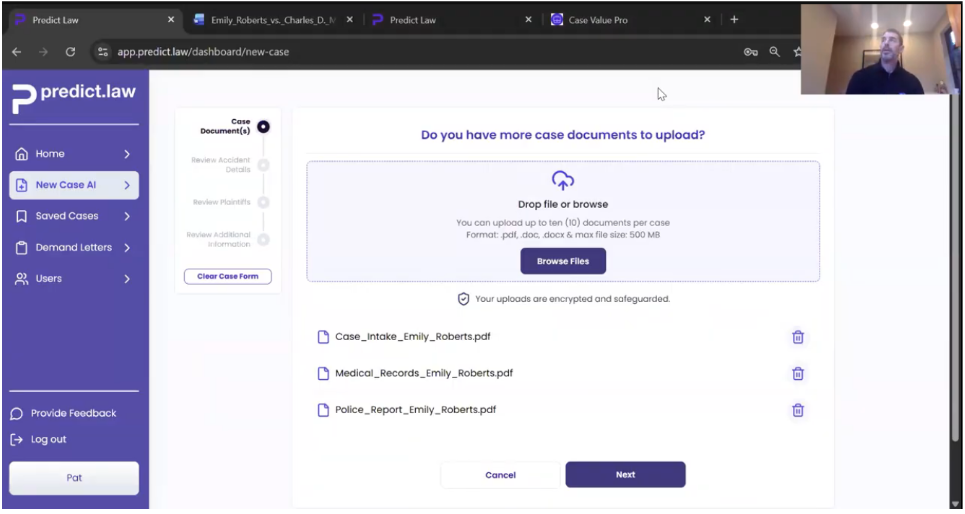
Let me show you what an actual case looks like. I’m going to start a new case. We heard overwhelmingly from attorneys that they prefer to use existing case documents, whatever they can, as opposed to manual entry. In this case, I’ve got a case for a new client, Emily Roberts, and we have an intake document, medical records, and a first report. We can handle up to ten documents, up to 100 pages per document, a thousand pages in total. Very quickly, as you’ll see here, in about five to ten seconds we’re able to understand the most relevant information from those documents to determine the fact pattern of this case.
In this example, our client is Emily Roberts. The defendant is Charles Mason. The jurisdiction for this case is Miami-Dade County in Florida. Our model trains on and predicts out the jurisdictional county level based on primary law from the counties.
Just a bit of context, which will matter as we move through this case: This case is from January 2025, in which our client was injured in a motor vehicle accident where the defendant driver was operating in the course of their employment for Walmart. This is a fictitious case to show you what the example looks like.
Case Questions and Details
As you move down here, you can see one of the questions we ask and have automatically pulled out from the case documents: “Was the defendant operating a commercial vehicle or performing a commercial work function?” All the questions we ask have been informed by interviews with practicing PI attorneys on the questions they ask in order to understand the likely value of a case.
You can see in this example there are no punitive damages likely based on the fact pattern thus far. Age and gender, and in this case, because it’s motor vehicle/motor transportation, are all captured as well . We find those to be minor predictive attributes. In total case volume, for example, the award potential for a minor who’s been injured may look different from an award value for an elderly person or an individual who was a pedestrian versus being in a vehicle.
Injury Assessment
What tends to drive more material weight in the case value is the injuries. Let’s spend a moment talking about the injuries in this case and how we use those injuries. In this case, our client Miss Roberts has suffered fractures to her ribs, a pulmonary contusion (that’s a lung bruise), an L4-L5 disc injury, and importantly—I’ll come back to this later—a type of nerve injury called radiculopathy, which you can see here.
What we do with this information is important. One, we pull out all the areas of the body that have been injured, which matters in terms of showing you similar precedent cases. But secondly, we create two injury severity scores based on an American Medical Association injury severity scoring guide for every case.
The reason we produce two scores: One is for the current impact of the injury. The second score is for the ongoing life impairment of the injury. For example, if a client had a fractured shoulder as part of a claim, both prompted appropriate medical care, and experienced a full recovery with no ongoing life impairment, it’s a very different case and a very different award value than perhaps a client with a compound leg fracture who, despite prompt and appropriate medical care, will experience an ongoing limp or change in their walk.
Every case is assessed against its near-term and long-term impact on the injuries they have suffered.
I’m gonna leave medical loss wages blank here in order to make the point that often when a case is first being evaluated by a firm or an attorney, the case is not far enough along its chronology to have a firm view on medical expenses or lost wages. That’s okay. What we do is we interpolate what are called the direct or special damages based on the remainder of the fact pattern surrounding this case, and then importantly, allow you to go back in later and create versions of this case to update the facts as medical and lost wages arrive and are available, to allow you to always update and revise the award value of your case as more information becomes available.
Case Prediction Results
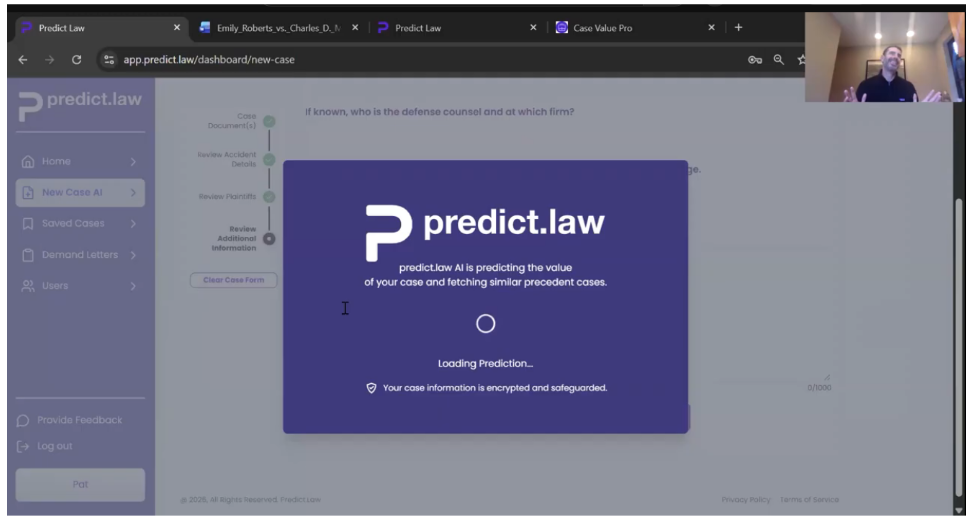
I want to move quickly and hit “predict case” here. What’s happening here—this takes about ten seconds—is we’re doing two things. One, we are evaluating the facts of your case against the relevant cases across 20,000+ precedent cases, about 200,000+ data points, as well as returning similar precedent cases to your case. In this example case with our client Miss Roberts: a $133,000 most likely award value if handled in Miami-Dade County in Florida, as is its jurisdiction.
Attorneys have told us knowing case value is highly important, but what’s also important is being able to defend the value of that case with the counterpart at the insurance company, the mediator, the arbitrator. For every case, what we see here is our proprietary similar case model returns similar cases to your case, obviously the same state, often in your same county of jurisdiction, with a similarity score based on the totality of the context and the facts of your case compared against the cases.
Case Comparison View
As an example, here’s a case of Pirritino vs Vargas—a $175,000 case. Let’s move down and look at what we call the case card view. On the left side, you’ve got our case, the Roberts versus Mason case. On the right side, you’ve got the most similar cases to your case.
Let’s find that Pirritino case I just mentioned. What you can see here is first you have the summary view of this case. We are very intentional about never having any of our users or law firms be the next law firm that experiences an adverse effect from bringing in a case reference into legal proceedings that is not grounded in a case number and is not, in fact, a real, actual precedent case.
You have the ability in the product to see more information about this case, including the attorneys involved, the law firm, the expert witnesses in the case. You see that as well. Importantly, there’s a side-by-side comparison view of your case on the left—this is our case—and the precedent case on the right, comparing the case across damages, defendants, the injury claims, the liability nature of the accident, any special circumstances that impacted the value of that case.
You may recall earlier in this discussion I mentioned a particular injury in our case—that L4-L5 disc injury with a nerve damage diagnosis called radiculopathy. Here we have in our precedent case the same C4-C5 disc injury and a lumbar radiculopathy as well. Imagine you’re an attorney defending the value of this case, and we’ve just given you in about ten seconds a spot-on precedent case with a similar injury profile, context, and jurisdiction to allow you to defend your award value.
Automated Workflows
Two things very quickly, and then I’ll open up for Q&A. What attorneys have asked us for is they’ll often say to us, “Well, you have my case documents. You know the value of my case. You have the most relevant precedent cases. Can you help me automate the next steps in handling this case on behalf of my client?”
One of the examples that we have built to accomplish that is the ability from the case screen to either create a demand letter or to create a case report very easily within the product.
When you create a demand letter on our platform, we do a couple of things that make us unique. One, because we have your case value, we automatically include the value of the case in the demand letter. But importantly, we also include the most similar precedent cases to your case in the demand letter. If you recall the Tino versus Vargas case that we just talked about, you can see that case has already been included in the demand letter—no additional work, automated process for the attorney to be more efficient in creating a strong evidence precedent point to pursue the higher value claim on behalf of their client.
I also mentioned the ability to create a case report. The case report produces all the information about your case as well as all the precedent cases—a 25-page PDF report in a professionally formatted report that you can then send to your client, to the counterparty. We had an attorney recently who sent one of our case reports to a litigation lender in order to provide them with the evidence points that they needed to support the approval of a loan decision associated with that case.
When you have this underlying AI data platform that can understand fact patterns, understand case value, understand precedent case fact patterns, it allows you to then begin to automate and extend a number of workflows off of that, all serving the interest of helping law firms move more efficiently and importantly helping them secure higher values on behalf of their clients.
I will pause there and open up for Q&A.
Q&A Session
Roland: This is great. Thank you, Pat. Very cool. The first question is from Marzieh and she’s asking where you are getting the data from. If I could just add to that question: If you’re taking data from court decisions, final judgments, how much does this reflect the entire world of cases that didn’t get to final judgment that were settled out of court?
Pat: Multiple pieces there. One, we have a licensing relationship with a national provider of outcomes. I’d say at this point we are probably 70% verdicts, 30% published settlements. We also pull from the county courts directly. We primarily use that for the ability to show court docket information directly in the product, which I’ll show you an example of here.
In parallel, we have had a number of plaintiff firms who have said to us, “Help us form a data consortium in which we share our firm’s case history,” which in many cases dates back 30 to 40 years in a properly anonymized manner, to have case volume precedent enriched by all the participating firms. What the plaintiff firms feel is an information asymmetry disadvantage versus the insurance firms, where the plaintiff firm sees maybe 50 cases a month and the insurance firms—State Farm, Allstate, and the like—have a data set that spans across 100,000+ cases, a million+ cases.
As a very recent example, I had a high-volume attorney in Florida who came to me and said, “I’d like to take the six highest volume PI firms in Florida, have us upload our case histories to your platform, and that allows us to then share in precedent case values, so we all have a stronger position against the insurance companies.”
We have another example of a lead intake firm who we are working with on the opportunity to upload and train on their 400,000 precedent cases in their operating history as well. Over time, this becomes a mix of the public record and their own operating history.
Just very briefly before the next question, I mentioned the court documents. If you look, for example, here, this is our Tino versus Vargas case. For higher-volume counties, we have the ability for you to actually go directly into the court docket for the case. In this case, there are 90 documents here. It gets a bit busy, but you have the ability to pull up quite easily the verdict documents.
If you want to get to ground truth on a precedent case—for example, the Tino versus Vargas case here—you can see in the product the actual filled jury verdict sheet for the precedent case across this case, the direct and the general damages, allowing you to really interrogate this case and importantly build ground truth confidence that you are working with a real-world precedent case and have all the details you need about the decision-making around that case.
Roland: One of the measurements—there’s a good question too. He’s asking now what about those cases that were actually not successful, the cases that were brought that were not successful? Where it’s not clear what caused the injury? How’s that getting accounted for in your model?
Pat: The current versions of our model do not predict liability. They are designed to understand the value of this case based on the context and the impact of the injuries for a successful outcome. We do capture and have access to cases in which the defense has been successful, which normally means there’s been a $0 outcome. On our roadmap is the ability to not just predict value but also predict win-loss likelihood as well. The current versions of the model focus on award value, not prediction on success of establishing liability.
Roland: Got it. Okay. Let me just jump to this question quickly and then get back to Russ’ point. B is highlighting that you identified the real pain points, and you addressed already, I think, the question of data quality and data robustness in light of the fact that insurances and law firm settlements are usually confidential. But what about the question of liability exposure? What if you make a wrong prediction that leads to malpractice claims? And then these other points: How do you relate to the larger platforms that can, as he points out, crush standalone tools? How do the terms of service kind of account for trying to limit your risk, that you’re not promising 100% accuracy?
Pat: That’s an important distinction to make. We are, as you mentioned, a decision support tool for licensed attorneys and law firms. We have not, for example, pursued an alternative business structure that may allow us to operate as an investor-owned law firm. We license to licensed attorneys. We are a tool for them to use to efficiently understand when to accept or decline or defer cases, as well as moving quickly to create the demand and ultimately either settle that case or decide if the settlement value is insufficient to move forward and file and litigate that case. But we are not autonomously making legal decisions. We are a support tool for licensed attorneys.
To the question on larger platforms, we pride ourselves on our ability to execute quickly and to be unencumbered by the technical debt that can often lead to slower pace of execution by larger established players. We see ourselves as a best-in-class solution for this area of legal work. As an example, we are in process with a high-volume firm who has said to us, “I would like to pair what you do with additional legal tech startups for medical chronologies and initial treatment and diagnosis to pull together best-of-breed across each of the areas of handling a case.”
What we hear from the market is less of an appetite for slower-moving incumbents and more of an appetite for “demonstrate that you’re best-of-breed in what you do.” That’s what tends to attract the interest.
Roland: Cool. Russ is asking how do you ensure that all leads are integrated into the portal like phone leads and web leads?
Pat: You have the ability as a customer of our product to replace the intake form on your front-end site with what we call our AI smart intake form. If you’ve ever been to a personal injury firm’s website, they’re often WordPress sites with fairly basic web form view—name and phone number, and what happened? Those leads will typically either go into email or will sit in a CRM system until a member of the firm’s able to work that lead.
In our case, if you deploy our AI smart intake form on your firm’s site, a minute after that consumer leaves your site, you’ll have the case value, precedent cases, and a full case report in your inbox.
As a real-world example of the pain point that has helped solve, I spoke to a national-level lead firm that told me they gave their call center the day off on Thanksgiving. A call came in Thanksgiving evening. A high-value opportunity was taken by the after-hours answering service. They followed up with that lead the morning after—that lead had already signed with the competition. That just goes to show you the importance of being able to accurately and quickly understand value on new leads.
Just as another example, we had an attorney who told us, “I could be anywhere in the world, and if you guys send me an email that says a $173,000 lead in my inbox, I’m stopping what I’m doing, I’m calling that client, and I’m sending out an engagement letter.”
Those anecdotes, for us, reinforce the value of being able to move as efficiently as possible to identify when a high-value lead has come in.
Roland: We’re already a little bit over time. I just want to—I saw Dave has been answering some of the questions that people asked in the chat. But how do you differentiate from other players, like Eve Legal and Suppio?
Pat: What we typically see is other legal tech players tend to have a center of gravity around certain things. For example, EvenUp has a center of gravity around the demand letter. Clio tends to have a center of gravity around medical chronologies. Where we like our position in the market is really before you even get to medical chronology or demand letter, the first question you’re asking is: Should I take this case in the first place? Where is this case likely worth?
In our view, that makes us one of the first legal tech products that are used when a new case comes in, and then allows us to offer additional value in the automation, in the analysis of the documents, perhaps with the demand letter, the case report, etc. We tend to like our position as one of the first products that a firm uses for a new case, and that gives us the ability to earn the right to be used in downstream portions of the case management workflow as well.
Roland: Okay. Well, maybe one more question. Based on my own experience, it appears to me that firms have their already homegrown algorithms, in a sense, for making a decision, even if not in a computer system. They have a way to determine whether to take a case or not. I was surprised that in theory we have this contingency fee system in the United States where technically this should give anyone access to legal representation. But then it’s also the case that firms will only take cases that are of a certain value.
You’re empowering the firms to make that decision even more clearly—they don’t make any errors. With your system, they can get a better prediction. But it doesn’t necessarily give people who have injuries that maybe are less than $100,000 or $50,000 or whatever the threshold is—it doesn’t necessarily give them access to attorneys. I was just wondering if you have any thoughts there. Eventually, will there be ways for—maybe it’s just self-represented litigation folks who can represent themselves with all the tools that are available out there? That’s an issue too, I think.
Pat: I think there are a couple things there. One, there are PI firms that specialize and may filter on a higher value. For example, you’ll come across a medical malpractice firm—there are all handled cases that are above a $1 million award opportunity.
One of the things that we expect to happen is, as our platform and other legal tech platforms allow cases to be worked more efficiently with less manpower, it does make it easier for firms to take on cases that may otherwise have not been worth the contingency fee investment of time—paralegals’ time, the research time, the document management time. The ability to automate the workflow around handling of documents, case value, creation of the demand, etc., lowers the cost, which lowers the risk of taking on lower-value contingency cases.
We hope this has the effect of allowing more cases—important to the individual but less high-value for the firm—to be taken on because the time investment and cost risk of taking on those cases becomes minimized with the AI-native and automation pieces available now.
Roland: Well, that’s an exciting vision. That’d be great if that was one of the outcomes. Well, Pat and Dave, thank you for joining us. Thank you for telling us about Predict.Law. It’s really cool. If folks wanted to reach out if they had any follow-up questions, what’s a good way to maybe—perhaps you could put your email into the chat?
Pat: It’s easy. I’m pat@predict.law
Roland: All right. Wonderful. Well, again, thank you. Quick round of applause on behalf of everyone. Good to see you. We’ll see everyone in early February. Also very soon we’ll be putting the agenda for our Future Law Conference in April on the website. Check it out—hopefully you will join us here in April. We are planning a really exciting program. Good to see you all. Thank you again.
Pat: Thank you.