Stanford Computational Antitrust offers to help antitrust agencies build their own digital brain
Palo Alto, April 22, 2026. Starting today, Stanford Computational Antitrust is available to help antitrust agencies worldwide build queryable knowledge systems from their own decisional records.
The offer follows a forthcoming guide in the Network Law Review by Thibault Schrepel, creator and director of the Stanford Computational Antitrust project. The build takes a few hours with very little technical skills.
To show what is possible, Dr. Schrepel built one such system from all European Commission competition decisions spanning 1977 to 2025. The system maps the corpus as an interactive knowledge graph. Each decision is a node. Each doctrinal link is an edge. Users can see at a glance which decisions the Commission’s own case law treats as foundational, and where its reasoning has drifted or fragmented over time.
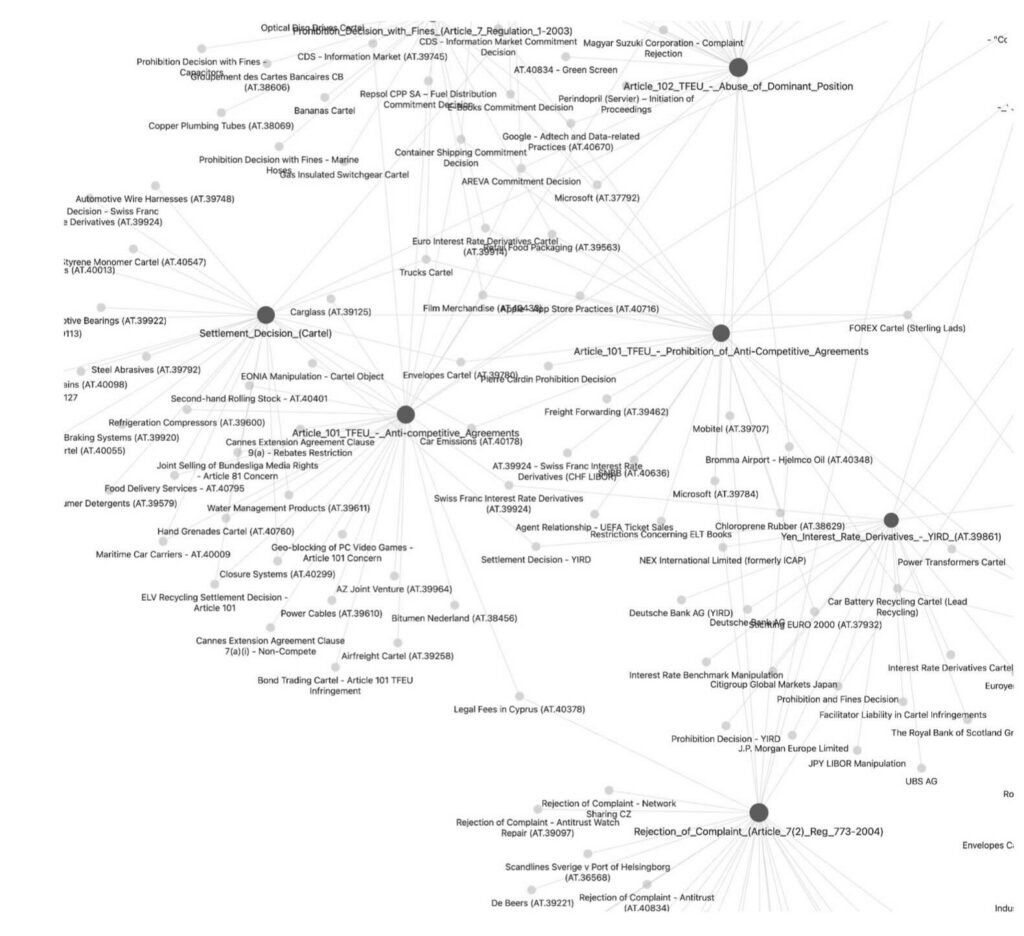
The best part comes next. The graph generates a private Wikipedia powered by the corpus. On demand, it produces a wiki page on any theme covered by the decisions, with cross-links to related topics and a master index. A user can ask for a page on ecosystem theories of harm. The system writes it from the decisions, cites the relevant cases, and links to every adjacent topic. Ask a follow-up question and the answer feeds back into the knowledge base as a new page. The more the system is used, the more connections it builds. It does not generate content beyond what the decisions contain. It does not hallucinate a case that does not exist.

The applications extend beyond research. Agencies can give the system to case handlers. A handler drafting an abuse of dominance decision can query every prior decision on market definition and identify where the reasoning has shifted. Court of appeals rulings can be integrated into the same graph. Handlers can see which theories survived appeal, which were reversed. Inconsistencies surface before a decision is issued rather than on appeal.
“Every competition agency faces the same problem,” said Schrepel. “Hundreds of decisions accumulated over decades. No one has read them all. No one remembers them in enough detail to catch contradictions as they emerge. A draft decision could be checked against the full decisional record before it is issued. Inconsistencies could surface before they reach appeal, not after.”
The project is open to partnering with agencies that want to build their own system. Each agency’s corpus is different. The methodology adapts to it. The project team will advise on design, corpus preparation, and deployment.
Agencies interested in exploring this should contact: schrepel@stanford.edu
The guide is available open access on SSRN: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6594359
Contact
Thibault Schrepel
schrepel@stanford.edu