Stanford NPE Litigation Database
About Us
The Stanford Non-Practicing Entity (NPE) Litigation Database (the “Database” and formerly known as the Stanford NPE Litigation Dataset) is the first ever publicly available database to track comprehensively how practicing entities, non-practicing entities, and patent assertion entities (PAEs) claim patent ownership rights in litigation. NPEs do not make products or offer services while PAEs—often referred to as “patent trolls”—employ patents primarily to obtain license fees, rather than support the transfer or commercialization of technology. Critics have come to believe that steadily increasing PAE enforcement activity, including litigation, is harming innovation and serving as a tax on producers and consumers. Stanford Law student researchers are tracking every lawsuit filed in U.S. district courts from 2000 to the present and identifying each patent plaintiff as either a practicing entity or as one of eleven types of NPEs. Categorization of all 43,000 lawsuits filed from 2007 to 2017 became publicly available on the project website in May 2019 and this full Database will continue to be updated with recent and future cases. For longer time series analysis, a 20% random sample of over 12,500 lawsuits filed from 2000 to 2017 is also available for download on the project website.
Stanford Law student researchers and Stanford IP Research Fellow Shawn Miller have coauthored Who’s Suing Us? Decoding Patent Plaintiffs since 2000 with the Stanford NPE Litigation Dataset (the project report). The project report includes detailed explanation of the motivations for creating the Database, the lawsuit categorization taxonomy and methodology, and quality control measures taken in constructing the Database.
The project report also includes descriptive statistics and trends in the share of U.S. patent litigation attributable to different types of patent owners using a 20% random sample of over 10,800 lawsuits filed from 2000 to 2015 that is available for download below. Our report reveals differences in patent litigation across each type of patent owner over the 16-year period, with a 3% margin of error. Key findings include:
- increased PAE litigation,
- decreased practicing entity litigation,
- nearly 80% of software litigation is PAE litigation,
- suits involving PAEs terminated faster than other entity suits, and
- the win rate for practicing entities is higher than that of PAEs.
As it becomes available, scholarship using the data will appear on this website.
Brief Database Methodology
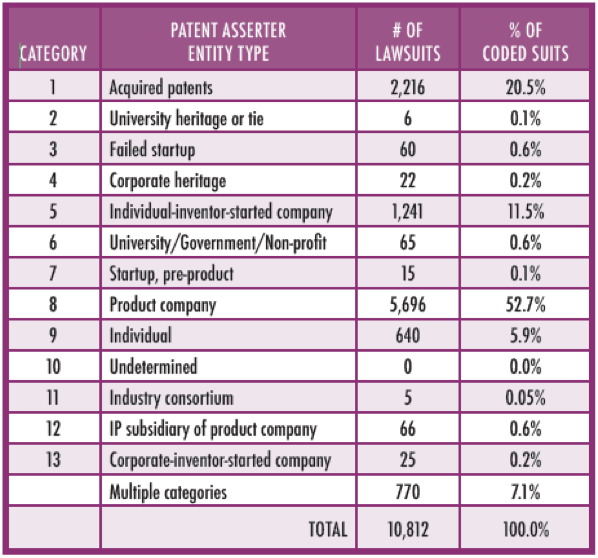
As detailed in the project report, each patent asserter involved in a lawsuit has been assigned to one of 13 categories (see Table 1) and coded into the Database via a user interface created specifically for this project. Each data point represents a lawsuit; some lawsuits contain multiple patent asserters and some of these multiple-asserter cases contain different types of patent owners. Such cases are assigned to multiple patent asserter categories.
Coders consulted several different sources to determine how to categorize each entity. First, coders reviewed key pleadings including the initial complaint. Second, coders identified the patents asserted in the lawsuit to check the Patent Office’s assignments database to obtain clues about the current owner type. Coders then conducted a comprehensive web search for each unknown patent asserter. After determining the proper categories for the patent asserters in each lawsuit, coders assigned the numbers for those categories to the patent asserters via the user interface.
Note: In our Key Findings, we define PAE lawsuits as those with category 1, 4 or 5 patent asserters. See Table 1 for the name of each patent asserter category.
Request Access to the NPE Litigation Database
Register to use the Database and download the data here.
Suggested Research Uses

The Database can aid Congress and the Patent Office in developing effective laws and policies and provides a valuable tool to help policy makers, scholars, and researchers better understand the nature of entities filing patent suits. By lending transparency to the amount and characteristics of PAE litigation, the Database can help resolve the fact or fiction of alleged PAE problems. Scholars, policy makers, and the public will benefit from better understanding that may, in turn, yield more effective policies, laws, and practices. Scholars can also use the Database to examine the effects of past patent reform actions, such as the AIA, on different types of patent owners.
Scholars
- Empirically confirm past research conclusions using the full population of lawsuits
- Conduct original research on differences in enforcement behavior across patent owner type
Policy Makers
- Develop a deeper understanding of the sources of patent enforcement costs given current rules
- Enhance and develop regulations and statutes

Sponsors and Partner
This project is made possible through the generosity of the Charles Koch Foundation and Lex Machina. The research is grounded in a four-year study by the Stanford Law and Policy Lab “Empirical Study of Patent Troll Litigation” Practicum.
