Student Post on Questions in Open-Source AI and Law
by Andrew Dang, 3L Student, Sandra Day O’Connor College of Law – Arizona State University
The emergence of Chat-GPT on November 30, 2022, presented businesses with a critical question: how much should they rely on Generative AI? In the legal field, the consensus is clear: AI won’t replace lawyers, but tech-savvy lawyers will likely outpace their peers who avoid it. Large Language Models (LLMs) such as GPT-4 are revolutionizing the industry by automating routine tasks like drafting documents and summarizing contracts. This wave of automation echoes the disruption Uber caused in transportation, but the legal field is poised to innovate rather than be overtaken. Leading legal organizations are already investing heavily in AI, with LexisNexis integrating AI and Thomson Reuters acquiring Casetext for $650 million, illustrating a survival-of-the-fittest scenario.
Yet adopting AI doesn’t ensure success; it requires ongoing adaptation. The legal battleground illustrates this well: if both sides use GPT-4, the advantage may neutralize, leading to a new phase of AI competition—customization. For legal generative AI to be an asset rather than a liability, it must be dependable and controllable. This is where open-source LLMs shine, offering transparency and adaptability, unlike closed-source models. As the legal sector navigates this new terrain, open-source AI seems to be the strategic choice for those aiming to stay competitive and compliant with evolving AI legislation.
The Case For Domain-Specific Models
One of the advantages of LLMs in the workplace is their ability to synthesize vast amounts of data, especially when implementing Retrieval Augmentation (RAG). LLMs are limited by their training data and prone to “hallucination,” but RAG can act as a pipeline between models and external databases. RAG is supported by technologies like vector databases, which store and manage data for efficient retrieval, and embedding models that help understand and categorize text. Despite the convenience of using the prevalence of proprietary closed-source models in RAG systems, organizations should consider the advantages of open-source alternatives.
Fine-tuned embedding models outperform generic models on domain-specific tasks, such as distinguishing legal facts from everyday facts. A proper understanding of the many technical terms in the law cannot be trained through generic datasets such as Wikipedia. Surface-level understanding proves insufficient for legal queries, which may seem simple but have layers of nuance. For example, if asked what a licensor must do if a licensee suggests improvements, embedding models might conflate “Licensor must incorporate enhancements into their data” with “Licensor keeps all rights not given to the licensee, and can use them freely.” The difference in the language is subtle, yet differences change the meaning of the clause.
Legal organizations can fine-tune open-source embedding models on domain-specific data to overcome the issues stated above. For example, embedding models, like Word2Vec, GloVe, and FastText, further trained on legal datasets, better capture legal language nuances. In addition, Legal BERT, a model pre-trained on the CaseHold dataset, outperformed ChatGPT on the LexGlue Benchmark. Furthermore, ranking third on MTBE’s benchmark is BAAI’s open-source bge-large-en-v1.5. Massive Text Embedding Benchmark (MTBE) evaluates eight tasks; “Bitext mining, Classification, Clustering, Pair Classification, Reranking, Retrieval, Semantic Textual Similarity, and Summarization.” We illustrated several examples of large language models and embedding models performing better when trained on domain-specific tasks. Applying the same principles, we can assume that the models leading the embedding benchmarks will perform better when trained on domain-specific tasks.
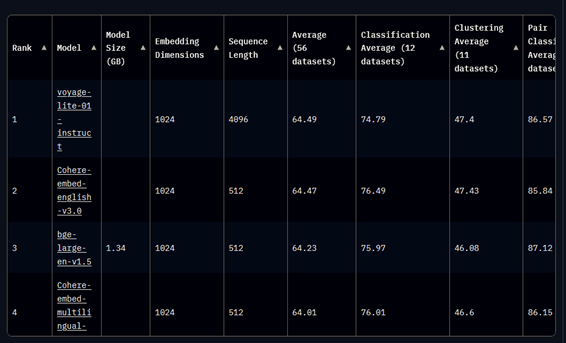
Big Tech and Big Data
Big Tech could allow fine-tuning for their embedding models. That said, for data privacy concerns, organizations should not give their proprietary data to Big Tech because of their lack of transparency. On the other hand, open-source models offer transparency and data security for legal organizations. User data is the new currency in this data economy, and legal organizations must protect confidential information. Legislative efforts like the European Artificial Intelligence Act (EU AI Act) impose transparency requirements on AI vendors like Big Tech. Drawing inspiration from the GDPR, the AI Act’s commitment to transparency reverberates throughout the legislation. The AI Act aims to protect “the fundamental rights and freedoms of natural people, particularly their right to protect personal data whenever their data is processed.
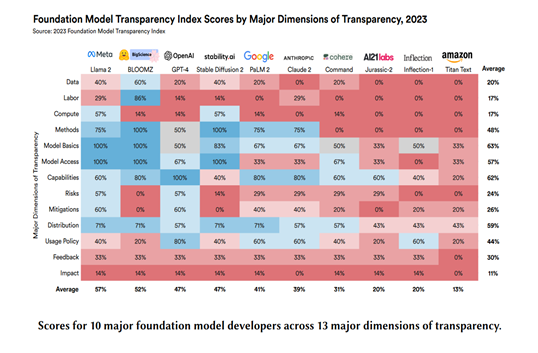
Even so, Stanford’s Transparency Index states that Big Tech’s foundation models fail to meet the EU AI Act’s transparency requirements. Big Tech’s lack of transparency around model architecture, training data, and evaluation data poses a risk for businesses relying on black-box models. This erodes trust among stakeholders and clients concerned about how their data is used and if AI systems could lead to discriminatory or harmful outcomes. A simple search into Google’s docket history reveals privacy violations. Google continues to violate data protection laws, as seen in Google LLC and YouTube, where both companies were fined $170 for violating the Children’s Online Privacy Protection Act. Another example is Google’s $5 billion lawsuit for tracking users’ incognito sessions in Brown v Google LLC.
OpenAI also lacks transparency. The lack of insight into OpenAI’s models makes it difficult to determine biases or flaws in the models’ outputs. Moreover, OpenAI’s sudden firing and re-hiring of Sam Altman is a cause for concern. Tech Companies are in an AI arms race to focus on profit over safety because of OpenAI’s release of ChatGPT. Despite OpenAI’s influence in the tech industry, OpenAI is silent about Altman’s firing, and the piece of information the public has is that Altman “was not consistently candid in his communications with the board, hindering its ability to exercise its responsibilities.”
The lack of transparency from Big Tech is concerning for stakeholders and clients. As data becomes the currency of the knowledge economy, businesses rely more on AI-powered solutions. But with the rise of black-box AI systems, there is a threat of third-party liability. Enterprises that rely on Big Tech’s models risk losing the trust of their stakeholders and clients, as they have valid concerns about how their data is used and whether AI systems could lead to discriminatory or harmful outcomes.
Data Privacy Laws
In the summer of 2023, OpenAI faced two class actions. Another class action was taken against Several states are following the EU’s privacy framework and enacting legislation to regulate AI technology’s “heightened risk of harm” and affirm individuals’ rights to personal information.
The legal landscape for AI and data privacy is evolving, with implications for how AI technologies are developed and used. Legal organizations must adapt to the changing legal environment and ensure their AI systems respect individuals’ creative contributions and data subjects’ privacy rights. Using open-source models can help companies tailor their AI systems to align with emerging state laws, especially in terms of respecting intellectual property and data privacy rights.
AI Alignment and the Adversarial Nature of the Law
A significant part of AI research is dedicated to AI alignment. AI alignment refers to developing AI systems whose behaviors and goals align with human values and ethics. At its core, AI alignment takes a harm reduction principle. The adversarial nature is deeply ingrained in the structure of the legal process. “By its adversarial nature, a litigation process requires both parties to exert efforts to increase their probability of winning.” While litigation leads to a “winner” and a “loser,” AI looks at scenarios from a neutral perspective to optimize user inputs towards the best outcome.
Legal organizations that remain complacent during this convergence will lose the adversarial battle, while proactive legal organizations will come out on top. A firm implementing its own AI system does not guarantee victory. Legal organizations must continuously train their AI models and update their systems. Yet the landscape of AI regulations and compliances still holds uncertainty. The U.S. might select a product liability approach, focusing AI regulations on products entering the commerce stream.
But Congress might align with the EU’s stance, extending compliance requirements to all AI systems. Amid this regulatory ambiguity, the case for developing domain-specific, open-source model becomes stronger. Such models allow for better control, tailored alignment with legal standards, and the flexibility to adapt to evolving regulations, thus positioning legal organizations on a more secure footing in the competitive and regulatory landscape.
Winning AI on “GPU Poor” Budget
Organizations are deliberating over how to implement generative AI into their infrastructure. For good reasons, most enterprises rely on third-party providers for AI integration. Vendors handle the GPU cost, bottlenecking developers. Integrating AI through an API is seamless compared to hosting a local source model. Running a large language model like LLaMa 2 or GPT-3.5 on a standard GPU-accelerated instance on AWS surpasses $2,000 per month. The cost to run GPT-4 is likely higher, exceeding $4,000 per month per instance. Organizations lack the hardware to use models out of the box and be “GPU-Poor” in this AI race.
In any event, Open-source frameworks can save legal organizations on cost. For example, LoRA and Q-LoRA are “GPU-Poor” staples for training models. LoRA eliminates hardware and performance issues by training only low-rank matrices instead of all the model’s parameters. Q-LoRA trains LoRA adapters with four-bit quantization, compressing the model to further save on memory. Tri Dao’s Flash-Attention 2 framework is another tool for the “GPU-Poor.” FlashAttention-2 delivers an astounding 2x speedup, achieved through improved parallelism and work partitioning. Flash-Attention 2 also lets developers replicate GPT3-175B training for 90% of the cost. Training LLMS like GPT-3 was estimated to cost $4,600,000. But FlashAttention-2 replicates the training at a fraction of the cost, at about $458,136. Organizations can use open-source resources such as the OpenAccess-AI-Collective’s Axolotl, which includes implementations of techniques like LoRA, Q-LoRA, and FlashAttention2 in their model training codes.
As for LLMs, a new paradigm is emerging where smaller models are outperforming models twice their size. Microsoft announced Phi 1.5, a 1.5 billion parameter size model. Despite Phi’s small size, Phi 1.5 outperformed Facebook/Meta’s Llama-2 seven billion parameter model.
Further reinforcing the idea that “bigger isn’t always better,” Mistral AI announced its first model, Mistral 7B. Mistral 7B performed better than all the models in the 7B category and even surpassed Facebook/Meta’s Llama2 13 B model on different benchmarks measuring diverse AI capabilities. Additionally, Zephyr 7b beta, a fine-tuned version of Mistral, outperforms Chat-GPT-3.5 and Llama-2-70b on several benchmarks.
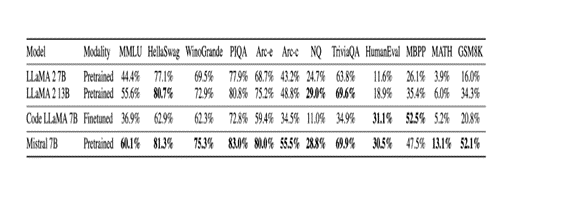
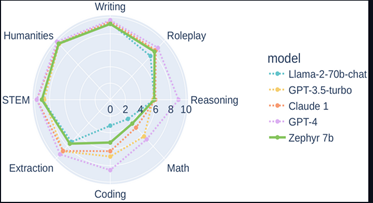
Strategically, organizations should deploy their own AI systems. Open-source frameworks will save organizations on hardware and token costs. Open-source models give legal organizations control to make revisions when needed, allowing for experimentation and implementing new methodologies rather than waiting on providers to update their model. The barriers to deploying and scaling AI models continue to decrease thanks to the open-source movement.
The Case for Open-Source LLMs
The effect of AI on the labor force cannot be ignored by any industry, and the legal sector is no exception. Organizations employing open-source large language models can effectively reduce risks associated with artificial intelligence.
Flagship embedding models excel in everyday tasks, yet the language complexities of law differ from everyday language. Embedding models that are fine-tuned are better suited for complex tasks required by the law. And the privacy concerns outweigh the advantages of fine-tuning closed-source embedding models. Company data, including client and trade secrets, must be protected from Big Tech. Big Tech’s lack of transparency and litigation history proves that Big Tech cannot be trusted with private data.
Additionally, legal organizations must prepare for regulatory changes that may affect their use of AI. Emerging privacy frameworks, such as the EU AI Act, underscore confidentiality, accountability, and transparency in AI deployments, aligning with the principles of open-source models. Yet the adversarial nature of legal practice poses unique challenges for AI alignment, as legal systems rely heavily on fixed and often opposing positions. A balanced approach that considers technological innovation, ethical considerations, and regulatory compliance is essential for incorporating AI. Legal organizations that invest in specialized knowledge, data curation, and open-source AI models will be better equipped to navigate the challenges ahead.
—————————————————————————————————————————————————-
[1] MTEB Leaderboard – a Hugging Face Space by mteb, https://huggingface.co/spaces/mteb/leaderboard (last visited Nov 28, 2023).
[2] Rishi Bommasani et al., The Foundation Model Transparency Index, (2023), http://arxiv.org/abs/2310.12941 (last visited Nov 27, 2023).
[3] Albert Q. Jiang et al., Mistral 7B, (2023), http://arxiv.org/abs/2310.06825 (last visited Nov 28, 2023).
[4] HuggingFaceH4/zephyr-7b-beta · Hugging Face, (2023), https://huggingface.co/HuggingFaceH4/zephyr-7b-beta (last visited Nov 28, 2023).