Breakthroughs in LLM Reasoning Show a Path Forward for Neuro-symbolic Legal AI
We recently presented our paper Equitable Access to Justice: Logical LLMs Show Promise at the NeurIPS 2024 workshop on System-2 Reasoning at Scale. This project was a group effort involving Manuj Kant, Dr. Marzieh Nabi, Manav Kant, Preston Carlson and Dr. Megan Ma.
Our team explored whether LLMs can assist in the creation of computable insurance contracts, which have the potential to demystify insurance for millions of Americans. We observed a massive leap in capability on this task from OpenAI’s GPT-4o (a traditional LLM) to OpenAI o1-preview (a reasoning LLM). OpenAI’s recent release of OpenAI o1 (which is better at reasoning than o1-preview) makes this result even more relevant today.
Our finding opens up many directions in the application of neuro-symbolic AI to legal problems, which we feel uniquely positioned to pursue with our combined background in law, logic programming and machine learning.
1. The Problem
According to a KFF (formerly Kaiser Family Foundation) study, a majority of Americans had problems with their health insurance over the course of a year. Many of these issues stemmed from uncertainty about what their policy covered and the extent of that coverage. This is an unfortunate reflection on the sometimes overwhelming complexity of health insurance policies.
But imagine a world in which insurance policies can be represented as computer programs. Then, coverage under a policy could be determined at the click of a button. Customers would be empowered to make more informed decisions about their choice of insurance and even to argue their case if denied coverage.
Unfortunately, although strides have been made in representing insurance policies as programs, document size and logical complexity have both been barriers to achieving this ideal.
2. Technical Approach
We believe that this problem calls for a neuro-symbolic approach. Machine learning models (including LLMs, or large language models), which operate by learning patterns (analogous to human neurology), can be considered neural AI. Logic programs, on the other hand, which derive conclusions purely through deduction on a set of facts, are considered symbolic AI. Because contracts rely both on human interpretation and logical deduction, neuro-symbolic approaches can be taken to represent them in code.
2a. Symbolic
Logic programming languages such as Prolog and Epilog, which are declarative in nature, have proven useful for formally representing (or encoding) contracts as code. These languages merely require the programmer to describe (declare) the logical relationships that define coverage for a given contract, as opposed to procedural languages such as C, Java and Python, which would require the programmer to delineate a set of instructions (procedure) to determine coverage. Considering the logical complexities of insurance contracts, the former approach is much cleaner. However, even with the power of declarative logic programming languages, encoding insurance policies is a time-intensive and difficult-to-scale process.
2b. Neural
This is where LLMs (large language models) enter the picture. With their ability to efficiently generate text, including code, these tools could serve as assistants in the process of computable contract encoding. But while LLMs have evolved to handle large text inputs, their reasoning abilities have traditionally been too weak to understand complex logic. The autoregressive nature of these models, which pushes them into greedily generating responses word-by-word rather than planning beforehand, may contribute to this limitation.
The OpenAI o1-preview model, however, stands to change the situation. This model has been trained specifically to spend time thinking about complex logical problems, which has massively enhanced its performance on reasoning benchmarks. Whereas GPT-4o may return an answer in seconds, OpenAI o1-preview can spend up to 30 seconds planning and searching before responding to a prompt. This offsets the greedy nature of autoregressive language models.
Given the heavy reasoning involved in encoding policies, we undertook a preliminary study comparing the efficacy of the OpenAI o1-preview reasoning model with GPT-4o on this task.
3. Experiment
3a. Approach
There are uncountably many ways in which LLMs can be leveraged as assistants for encoding insurance contracts. They can be assigned broader or narrower tasks at earlier or later stages of the process, prompted in myriad ways with various kinds and levels of technical and legal context, etc. Given this complexity, a first step in determining the capabilities of an LLM to assist in the encoding of insurance contracts is to see whether it can independently encode a relatively simple contract from a relatively simple prompt.

Figure 1. The policy encoding process.
In this vein, we chose to have both LLMs (4o and o1-preview) generate encodings on a simplified version of the Chubb Hospital Cash Benefit policy with minimal context given about the policy or the desired structure of the generated code.
3b. Qualitative Analysis
Simply put, we found that o1-preview did much better than 4o. The following graph representations illustrate the structure of the code generated by each model.

Figure 2. Policy encodings generated by GPT-4o (left) and OpenAI o1-preview (right).
From a visual standpoint, whereas 4o’s encoding looks like a tangled mess of wires, o1-preview’s is a cleanly routed system. To better understand the logical differences, consider the following excerpt from Section 1.3 of the Chubb hospital cash benefit policy:
“No later than the 7th month anniversary of the policy’s effective date, written confirmation from the medical provider regarding a wellness visit within 6 months must be supplied.”
This single sentence stipulates two intertwined temporal conditions – one for the wellness visit (within 6 months) and one for the confirmation of the visit (within 7 months). OpenAI o1-preview successfully encoded both conditions (VisitTime =< 183 and ConfirmTime =< 213, respectively). But while GPT-4o checked that Month =< 6 for the visit, it had no encoding for the confirmation. The inability to disentangle these conditions is a consistent problem with GPT-4o’s encodings of this policy. Furthermore, GPT-4o spent twice as many lines of code as OpenAI o1-preview on its logically inferior encoding. These observations highlight the contrast between the strategic, logical approach of o1-preview with that of 4o, which seems to dive into a complex task without first evaluating the best strategy to use.
3c. Empirical Analysis
In addition to our qualitative analysis, we devised an experimental method to understand the quality (in terms of interpretability and accuracy) of the generated policy encodings and the ability of both LLMs to reason on their respective encodings.
We first put together a set of nine questions, or claims, regarding the coverage provided by the simplified Chubb policy – specifically, whether the policy would provide coverage in given hypothetical situations. Then, we asked both LLMs to generate claim encodings, or representations of the questions as logic queries, to be executed on their own policy encodings.
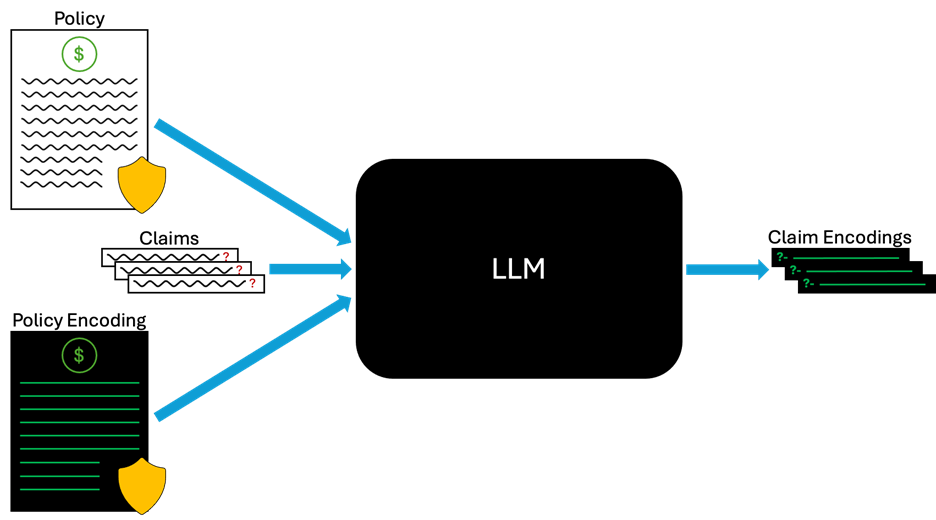
Finally, we executed each model’s claim encodings on their respective policy encodings through the SWISH-Prolog interpreter, counting the number of correctly adjudicated claims.

We found that the policy and claim encodings generated by OpenAI o1-preview were very likely to yield the correct adjudications, at an average of 83%. GPT-4o, on the other hand, had a relatively dismal record, at about 27% adjudication accuracy. It is worth noting that 4 of the policy encodings generated by GPT-4o were not executable due to invalid syntax, so none of the claims against those policies were correctly adjudicated. But even the syntactically correct policy encodings generated by GPT-4o only yielded correct adjudications 44% of the time.

4. Can LLMs do it all?
The enhanced ability of OpenAI o1-preview on encoding policies implies that it has a much greater understanding of their logical complexities than previous models. This begs the question… Can LLMs do it all? Can we bypass the process of representing contracts as logic programs and have reasoning LLMs adjudicate claims directly? This is a question we hope to explore in our future studies.
However, cost, interpretability and verifiability are all glaring potential issues with this approach.
With the amount of inference-time compute that reasoning LLMs require to generate responses, inference costs for claim adjudication at scale would be high. On the other hand, leveraging this expensive inference-time compute to generate a single logic program, which can then be used to adjudicate claims (at almost no cost), is comparatively inexpensive.
Furthermore, the sensitive nature of legal queries necessitates a system whose decisions are traceable and interpretable. Despite progress in methodologies such as RAG (which guides LLMs to retrieve information from credible sources) hallucinations can and do occur, including in the legal domain. Logic programs, on the other hand, are much easier to verify and regulate, and interpreters can tell us exactly why any given decision was made.
5. Conclusion and Future Directions
In this preliminary study, we observed a massive improvement in policy encoding capabilities from GPT-4o to OpenAI o1-preview. Thus, reasoning models could be a crucial resource for achieving efficient, scalable production of computable contracts. This is especially exciting since the recently released OpenAI o1 is much better than o1-preview at many reasoning tasks.
We are now experimenting with these models on encoding longer, more complex contracts, and also hope to study how LLMs and logic programs can be combined to adjudicate claims.